TorchVision 目标检测微调教程
在本教程中,我们将使用预训练的 Mask R-CNN 模型在 Penn-Fudan 行人检测与分割数据库 上进行微调。该数据库包含 170 张图像,其中有 345 个行人实例。我们将通过它来演示如何使用 torchvision 中的新功能,在自定义数据集上训练目标检测和实例分割模型。
本教程仅适用于 torchvision 版本 >=0.16 或 nightly 版本。如果您使用的是 torchvision<=0.15,请参考 此教程。
定义数据集
用于训练目标检测、实例分割和人体关键点检测的参考脚本使得轻松支持添加新的自定义数据集成为可能。数据集应继承自标准的 torch.utils.data.Dataset 类,并实现 __len__ 和 __getitem__ 方法。
我们唯一的要求是数据集的 __getitem__ 方法应返回一个元组:
-
图像: 形状为
[3, H, W]的torchvision.tv_tensors.Image、纯张量,或大小为(H, W)的 PIL 图像 -
目标:包含以下字段的字典
-
boxes,torchvision.tv_tensors.BoundingBoxes形状为[N, 4]:N个边界框的坐标,格式为[x0, y0, x1, y1],范围从0到W和0到H。 -
labels, 整数torch.Tensor形状为[N]:每个边界框的标签。0始终表示背景类别。 -
image_id, 整数:图像标识符。它在数据集中所有图像之间应是唯一的,并在评估期间使用。 -
area, 浮点数torch.Tensor形状为[N]:边界框的面积。这在评估时与 COCO 指标一起使用,以区分小、中、大框的得分。 -
iscrowd, uint8torch.Tensor形状为[N]:iscrowd=True的实例在评估期间将被忽略。 -
(可选的)
masks,torchvision.tv_tensors.Mask形状为[N, H, W]:每个对象的分割掩码。
-
如果您的数据集符合上述要求,那么它将适用于参考脚本中的训练和评估代码。评估代码将使用来自 pycocotools 的脚本,您可以通过 pip install pycocotools 进行安装。
对于 Windows 系统,请使用以下命令从 gautamchitnis 安装
pycocotools:
pip install git+https://github.com/gautamchitnis/cocoapi.git@cocodataset-master#subdirectory=PythonAPI
关于labels的一点说明:模型将类别0视为背景。如果您的数据集中不包含背景类别,则labels中不应包含0。例如,假设您只有两个类别,猫和狗,您可以定义1(而不是0)来表示猫,2来表示狗。因此,如果某张图像中同时包含这两个类别,您的labels张量应类似于[1, 2]。
此外,如果您希望在训练期间使用宽高比分组(即每个批次仅包含具有相似宽高比的图像),则建议同时实现一个get_height_and_width方法,该方法返回图像的高度和宽度。如果未提供此方法,我们将通过__getitem__查询数据集中的所有元素,这会加载图像到内存中,相比提供自定义方法来说速度较慢。
为 PennFudan 编写自定义数据集
让我们为 PennFudan 数据集编写一个数据集。首先,下载数据集并解压 zip 文件:
wget https://www.cis.upenn.edu/~jshi/ped_html/PennFudanPed.zip -P data
cd data && unzip PennFudanPed.zip
我们有以下文件夹结构:
PennFudanPed/
PedMasks/
FudanPed00001_mask.png
FudanPed00002_mask.png
FudanPed00003_mask.png
FudanPed00004_mask.png
...
PNGImages/
FudanPed00001.png
FudanPed00002.png
FudanPed00003.png
FudanPed00004.png
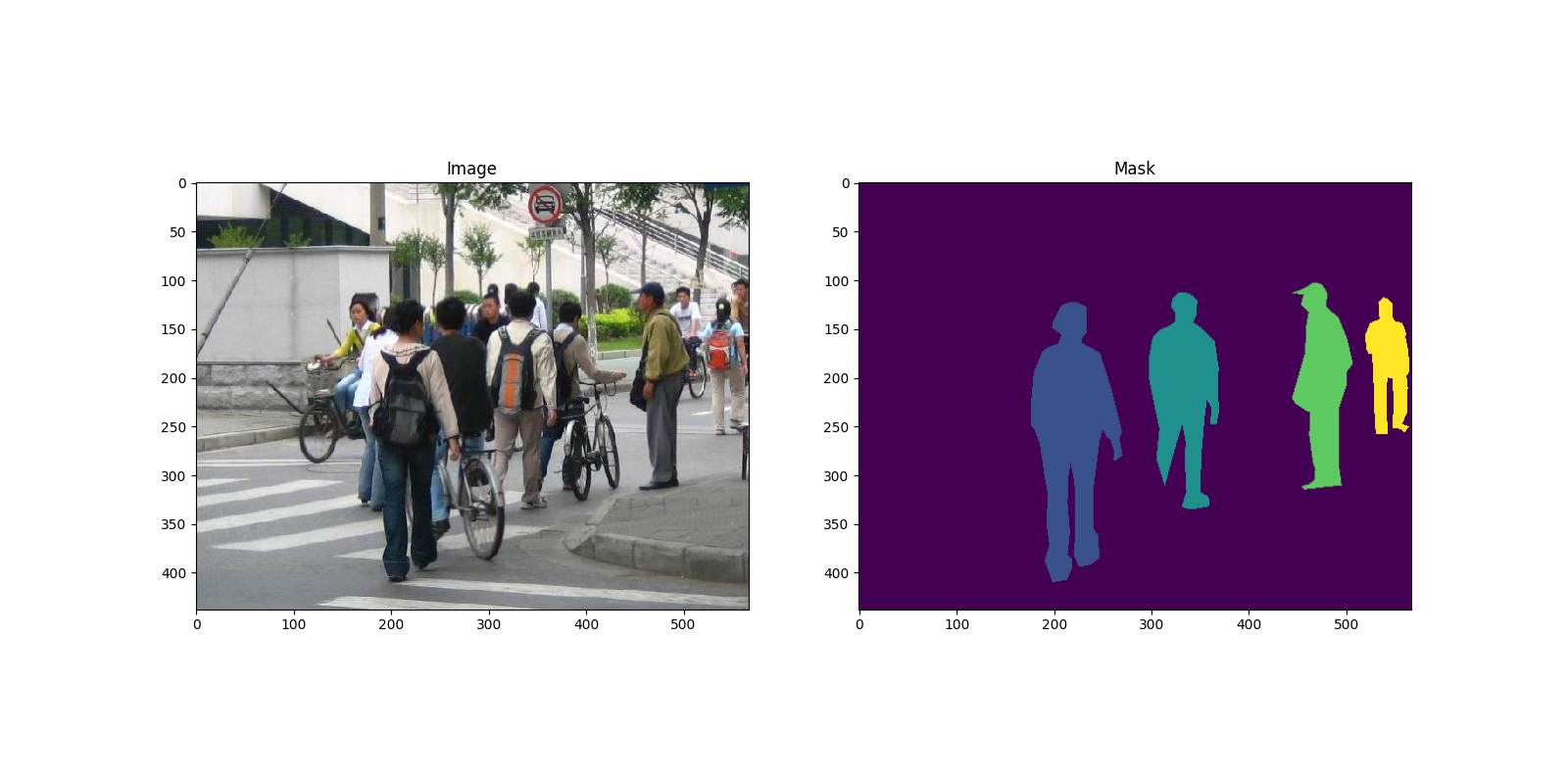
这是一组图像和分割掩码的示例
importmatplotlib.pyplotasplt
fromtorchvision.ioimport read_image
image = read_image("data/PennFudanPed/PNGImages/FudanPed00046.png")
mask = read_image("data/PennFudanPed/PedMasks/FudanPed00046_mask.png")
plt.figure(figsize=(16, 8))
plt.subplot(121)
plt.title("Image")
plt.imshow(image.permute(1, 2, 0))
plt.subplot(122)
plt.title("Mask")
plt.imshow(mask.permute(1, 2, 0))
<matplotlib.image.AxesImage object at 0x7f9938baf1c0>
因此,每张图像都有对应的分割掩码,其中每种颜色对应不同的实例。让我们为这个数据集编写一个 torch.utils.data.Dataset 类。在下面的代码中,我们将图像、边界框和掩码包装到 torchvision.tv_tensors.TVTensor 类中,以便能够为给定的目标检测和分割任务应用 torchvision 内置的转换(新的转换 API)。具体来说,图像张量将被 torchvision.tv_tensors.Image 包装,边界框被 torchvision.tv_tensors.BoundingBoxes 包装,掩码被 torchvision.tv_tensors.Mask 包装。由于 torchvision.tv_tensors.TVTensor 是 torch.Tensor 的子类,包装后的对象也是张量,并继承了普通的 torch.Tensor API。有关 torchvision tv_tensors 的更多信息,请参阅此文档。
importos
importtorch
fromtorchvision.ioimport read_image
fromtorchvision.ops.boxesimport masks_to_boxes
fromtorchvisionimport tv_tensors
fromtorchvision.transforms.v2import functional as F
classPennFudanDataset(torch.utils.data.Dataset):
def__init__(self, root, transforms):
self.root = root
self.transforms = transforms
# load all image files, sorting them to
# ensure that they are aligned
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages"))))
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks"))))
def__getitem__(self, idx):
# load images and masks
img_path = os.path.join(self.root, "PNGImages", self.imgs[idx])
mask_path = os.path.join(self.root, "PedMasks", self.masks[idx])
img = read_image(img_path)
mask = read_image(mask_path)
# instances are encoded as different colors
obj_ids = torch.unique(mask)
# first id is the background, so remove it
obj_ids = obj_ids[1:]
num_objs = len(obj_ids)
# split the color-encoded mask into a set
# of binary masks
masks = (mask == obj_ids[:, None, None]).to(dtype=torch.uint8)
# get bounding box coordinates for each mask
boxes = masks_to_boxes(masks)
# there is only one class
labels = torch.ones((num_objs,), dtype=torch.int64)
image_id = idx
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# suppose all instances are not crowd
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
# Wrap sample and targets into torchvision tv_tensors:
img = tv_tensors.Image(img)
target = {}
target["boxes"] = tv_tensors.BoundingBoxes(boxes, format="XYXY", canvas_size=F.get_size(img))
target["masks"] = tv_tensors.Mask(masks)
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def__len__(self):
return len(self.imgs)
以上就是数据集的内容。接下来,让我们定义一个可以对该数据集进行预测的模型。
定义模型
在本教程中,我们将使用基于 Faster R-CNN 的 Mask R-CNN。Faster R-CNN 是一个能够预测图像中潜在对象的边界框和类别分数的模型。

Mask R-CNN 在 Faster R-CNN 的基础上增加了一个额外的分支,用于预测每个实例的分割掩码。

在 TorchVision Model Zoo 中修改现有模型时,通常有两种常见情况。第一种情况是,我们希望从一个预训练模型开始,仅微调最后一层。另一种情况是,我们希望将模型的骨干网络替换为不同的骨干网络(例如,为了加快预测速度)。
在接下来的部分中,我们将看看如何实现这些操作。
1 - 从预训练模型进行微调
假设您想从一个在 COCO 数据集上预训练的模型开始,并希望针对您的特定类别进行微调。以下是实现这一目标的一种可能方法:
importtorchvision
fromtorchvision.models.detection.faster_rcnnimport FastRCNNPredictor
# load a model pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(weights="DEFAULT")
# replace the classifier with a new one, that has
# num_classes which is user-defined
num_classes = 2 # 1 class (person) + background
# get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
Downloading: "https://download.pytorch.org/models/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth" to /var/lib/ci-user/.cache/torch/hub/checkpoints/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
0%| | 0.00/160M [00:00<?, ?B/s]
12%|#2 | 19.4M/160M [00:00<00:00, 203MB/s]
25%|##4 | 39.2M/160M [00:00<00:00, 205MB/s]
52%|#####1 | 82.6M/160M [00:00<00:00, 318MB/s]
79%|#######8 | 126M/160M [00:00<00:00, 372MB/s]
100%|##########| 160M/160M [00:00<00:00, 350MB/s]
2 - 修改模型以添加不同的骨干网络
importtorchvision
fromtorchvision.models.detectionimport FasterRCNN
fromtorchvision.models.detection.rpnimport AnchorGenerator
# load a pre-trained model for classification and return
# only the features
backbone = torchvision.models.mobilenet_v2(weights="DEFAULT").features
# ``FasterRCNN`` needs to know the number of
# output channels in a backbone. For mobilenet_v2, it's 1280
# so we need to add it here
backbone.out_channels = 1280
# let's make the RPN generate 5 x 3 anchors per spatial
# location, with 5 different sizes and 3 different aspect
# ratios. We have a Tuple[Tuple[int]] because each feature
# map could potentially have different sizes and
# aspect ratios
anchor_generator = AnchorGenerator(
sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),)
)
# let's define what are the feature maps that we will
# use to perform the region of interest cropping, as well as
# the size of the crop after rescaling.
# if your backbone returns a Tensor, featmap_names is expected to
# be [0]. More generally, the backbone should return an
# ``OrderedDict[Tensor]``, and in ``featmap_names`` you can choose which
# feature maps to use.
roi_pooler = torchvision.ops.MultiScaleRoIAlign(
featmap_names=['0'],
output_size=7,
sampling_ratio=2
)
# put the pieces together inside a Faster-RCNN model
model = FasterRCNN(
backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler
)
Downloading: "https://download.pytorch.org/models/mobilenet_v2-7ebf99e0.pth" to /var/lib/ci-user/.cache/torch/hub/checkpoints/mobilenet_v2-7ebf99e0.pth
0%| | 0.00/13.6M [00:00<?, ?B/s]
100%|##########| 13.6M/13.6M [00:00<00:00, 273MB/s]
PennFudan 数据集的目标检测与实例分割模型
在我们的案例中,由于数据集非常小,我们希望从预训练模型进行微调,因此我们将采用第一种方法。
这里我们还希望计算实例分割掩码,因此我们将使用 Mask R-CNN:
importtorchvision
fromtorchvision.models.detection.faster_rcnnimport FastRCNNPredictor
fromtorchvision.models.detection.mask_rcnnimport MaskRCNNPredictor
defget_model_instance_segmentation(num_classes):
# load an instance segmentation model pre-trained on COCO
model = torchvision.models.detection.maskrcnn_resnet50_fpn(weights="DEFAULT")
# get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# now get the number of input features for the mask classifier
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
# and replace the mask predictor with a new one
model.roi_heads.mask_predictor = MaskRCNNPredictor(
in_features_mask,
hidden_layer,
num_classes
)
return model
这样,model 就可以准备好用于在您的自定义数据集上进行训练和评估了。
整合所有内容
在 references/detection/ 目录下,我们提供了许多辅助函数来简化和训练检测模型。这里,我们将使用 references/detection/engine.py 和 references/detection/utils.py 文件。只需将 references/detection 目录下的所有内容下载到您的文件夹中,并在此处使用它们。在 Linux 系统上,如果您安装了 wget,可以使用以下命令进行下载:
os.system("wget https://raw.githubusercontent.com/pytorch/vision/main/references/detection/engine.py")
os.system("wget https://raw.githubusercontent.com/pytorch/vision/main/references/detection/utils.py")
os.system("wget https://raw.githubusercontent.com/pytorch/vision/main/references/detection/coco_utils.py")
os.system("wget https://raw.githubusercontent.com/pytorch/vision/main/references/detection/coco_eval.py")
os.system("wget https://raw.githubusercontent.com/pytorch/vision/main/references/detection/transforms.py")
0
自 v0.15.0 版本起,torchvision 提供了 新的 Transforms API,以便轻松编写用于目标检测和分割任务的数据增强流程。
让我们编写一些用于数据增强/转换的辅助函数:
fromtorchvision.transformsimport v2 as T
defget_transform(train):
transforms = []
if train:
transforms.append(T.RandomHorizontalFlip(0.5))
transforms.append(T.ToDtype(torch.float, scale=True))
transforms.append(T.ToPureTensor())
return T.Compose(transforms)
测试 forward() 方法(可选)
在遍历数据集之前,最好先了解模型在训练和推理时对样本数据的期望。
importutils
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(weights="DEFAULT")
dataset = PennFudanDataset('data/PennFudanPed', get_transform(train=True))
data_loader = torch.utils.data.DataLoader(
dataset,
batch_size=2,
shuffle=True,
collate_fn=utils.collate_fn
)
# For Training
images, targets = next(iter(data_loader))
images = list(image for image in images)
targets = [{k: v for k, v in t.items()} for t in targets]
output = model(images, targets) # Returns losses and detections
print(output)
# For inference
model.eval()
x = [torch.rand(3, 300, 400), torch.rand(3, 500, 400)]
predictions = model(x) # Returns predictions
print(predictions[0])
{'loss_classifier': tensor(0.0808, grad_fn=<NllLossBackward0>), 'loss_box_reg': tensor(0.0284, grad_fn=<DivBackward0>), 'loss_objectness': tensor(0.0186, grad_fn=<BinaryCrossEntropyWithLogitsBackward0>), 'loss_rpn_box_reg': tensor(0.0034, grad_fn=<DivBackward0>)}
{'boxes': tensor([], size=(0, 4), grad_fn=<StackBackward0>), 'labels': tensor([], dtype=torch.int64), 'scores': tensor([], grad_fn=<IndexBackward0>)}
现在让我们编写执行训练和验证的主函数:
fromengineimport train_one_epoch, evaluate
# train on the GPU or on the CPU, if a GPU is not available
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# our dataset has two classes only - background and person
num_classes = 2
# use our dataset and defined transformations
dataset = PennFudanDataset('data/PennFudanPed', get_transform(train=True))
dataset_test = PennFudanDataset('data/PennFudanPed', get_transform(train=False))
# split the dataset in train and test set
indices = torch.randperm(len(dataset)).tolist()
dataset = torch.utils.data.Subset(dataset, indices[:-50])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-50:])
# define training and validation data loaders
data_loader = torch.utils.data.DataLoader(
dataset,
batch_size=2,
shuffle=True,
collate_fn=utils.collate_fn
)
data_loader_test = torch.utils.data.DataLoader(
dataset_test,
batch_size=1,
shuffle=False,
collate_fn=utils.collate_fn
)
# get the model using our helper function
model = get_model_instance_segmentation(num_classes)
# move model to the right device
model.to(device)
# construct an optimizer
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(
params,
lr=0.005,
momentum=0.9,
weight_decay=0.0005
)
# and a learning rate scheduler
lr_scheduler = torch.optim.lr_scheduler.StepLR(
optimizer,
step_size=3,
gamma=0.1
)
# let's train it just for 2 epochs
num_epochs = 2
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, data_loader_test, device=device)
print("That's it!")
Downloading: "https://download.pytorch.org/models/maskrcnn_resnet50_fpn_coco-bf2d0c1e.pth" to /var/lib/ci-user/.cache/torch/hub/checkpoints/maskrcnn_resnet50_fpn_coco-bf2d0c1e.pth
0%| | 0.00/170M [00:00<?, ?B/s]
21%|## | 35.6M/170M [00:00<00:00, 373MB/s]
44%|####4 | 75.5M/170M [00:00<00:00, 399MB/s]
68%|######7 | 115M/170M [00:00<00:00, 407MB/s]
91%|#########1| 155M/170M [00:00<00:00, 411MB/s]
100%|##########| 170M/170M [00:00<00:00, 407MB/s]
/var/lib/workspace/intermediate_source/engine.py:30: FutureWarning:
`torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
Epoch: [0] [ 0/60] eta: 0:00:23 lr: 0.000090 loss: 4.9024 (4.9024) loss_classifier: 0.4325 (0.4325) loss_box_reg: 0.1060 (0.1060) loss_mask: 4.3588 (4.3588) loss_objectness: 0.0028 (0.0028) loss_rpn_box_reg: 0.0023 (0.0023) time: 0.3951 data: 0.0134 max mem: 2430
Epoch: [0] [10/60] eta: 0:00:11 lr: 0.000936 loss: 1.7781 (2.7694) loss_classifier: 0.4105 (0.3552) loss_box_reg: 0.3052 (0.2540) loss_mask: 0.9491 (2.1320) loss_objectness: 0.0219 (0.0214) loss_rpn_box_reg: 0.0056 (0.0069) time: 0.2278 data: 0.0149 max mem: 2599
Epoch: [0] [20/60] eta: 0:00:08 lr: 0.001783 loss: 0.8086 (1.7883) loss_classifier: 0.2145 (0.2678) loss_box_reg: 0.2062 (0.2330) loss_mask: 0.3975 (1.2592) loss_objectness: 0.0134 (0.0202) loss_rpn_box_reg: 0.0076 (0.0080) time: 0.2076 data: 0.0152 max mem: 2624
Epoch: [0] [30/60] eta: 0:00:06 lr: 0.002629 loss: 0.6825 (1.4259) loss_classifier: 0.1407 (0.2256) loss_box_reg: 0.2295 (0.2427) loss_mask: 0.2608 (0.9280) loss_objectness: 0.0182 (0.0197) loss_rpn_box_reg: 0.0101 (0.0099) time: 0.2117 data: 0.0162 max mem: 2772
Epoch: [0] [40/60] eta: 0:00:04 lr: 0.003476 loss: 0.5475 (1.2049) loss_classifier: 0.0954 (0.1908) loss_box_reg: 0.2464 (0.2343) loss_mask: 0.2259 (0.7539) loss_objectness: 0.0121 (0.0162) loss_rpn_box_reg: 0.0119 (0.0098) time: 0.2108 data: 0.0166 max mem: 2772
Epoch: [0] [50/60] eta: 0:00:02 lr: 0.004323 loss: 0.3637 (1.0395) loss_classifier: 0.0571 (0.1626) loss_box_reg: 0.1473 (0.2160) loss_mask: 0.1626 (0.6380) loss_objectness: 0.0033 (0.0136) loss_rpn_box_reg: 0.0070 (0.0093) time: 0.2056 data: 0.0160 max mem: 2772
Epoch: [0] [59/60] eta: 0:00:00 lr: 0.005000 loss: 0.3524 (0.9405) loss_classifier: 0.0436 (0.1447) loss_box_reg: 0.1261 (0.2039) loss_mask: 0.1588 (0.5711) loss_objectness: 0.0021 (0.0119) loss_rpn_box_reg: 0.0065 (0.0089) time: 0.2025 data: 0.0152 max mem: 2772
Epoch: [0] Total time: 0:00:12 (0.2105 s / it)
creating index...
index created!
Test: [ 0/50] eta: 0:00:04 model_time: 0.0790 (0.0790) evaluator_time: 0.0063 (0.0063) time: 0.0981 data: 0.0123 max mem: 2772
Test: [49/50] eta: 0:00:00 model_time: 0.0426 (0.0576) evaluator_time: 0.0046 (0.0069) time: 0.0644 data: 0.0097 max mem: 2772
Test: Total time: 0:00:03 (0.0758 s / it)
Averaged stats: model_time: 0.0426 (0.0576) evaluator_time: 0.0046 (0.0069)
Accumulating evaluation results...
DONE (t=0.01s).
Accumulating evaluation results...
DONE (t=0.01s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.640
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.984
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.848
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.288
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.602
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.652
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.282
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.690
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.690
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.367
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.675
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.700
IoU metric: segm
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.671
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.973
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.777
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.394
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.512
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.686
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.294
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.721
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.724
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.633
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.667
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.732
Epoch: [1] [ 0/60] eta: 0:00:10 lr: 0.005000 loss: 0.2559 (0.2559) loss_classifier: 0.0163 (0.0163) loss_box_reg: 0.0581 (0.0581) loss_mask: 0.1781 (0.1781) loss_objectness: 0.0001 (0.0001) loss_rpn_box_reg: 0.0032 (0.0032) time: 0.1806 data: 0.0141 max mem: 2772
Epoch: [1] [10/60] eta: 0:00:10 lr: 0.005000 loss: 0.3345 (0.3715) loss_classifier: 0.0429 (0.0519) loss_box_reg: 0.1324 (0.1418) loss_mask: 0.1625 (0.1663) loss_objectness: 0.0017 (0.0031) loss_rpn_box_reg: 0.0084 (0.0084) time: 0.2089 data: 0.0163 max mem: 2772
Epoch: [1] [20/60] eta: 0:00:08 lr: 0.005000 loss: 0.3345 (0.3480) loss_classifier: 0.0388 (0.0449) loss_box_reg: 0.1140 (0.1168) loss_mask: 0.1705 (0.1770) loss_objectness: 0.0013 (0.0022) loss_rpn_box_reg: 0.0071 (0.0072) time: 0.2052 data: 0.0154 max mem: 2772
Epoch: [1] [30/60] eta: 0:00:06 lr: 0.005000 loss: 0.3144 (0.3296) loss_classifier: 0.0379 (0.0441) loss_box_reg: 0.0880 (0.1113) loss_mask: 0.1495 (0.1651) loss_objectness: 0.0010 (0.0023) loss_rpn_box_reg: 0.0043 (0.0069) time: 0.2047 data: 0.0154 max mem: 2772
Epoch: [1] [40/60] eta: 0:00:04 lr: 0.005000 loss: 0.3032 (0.3253) loss_classifier: 0.0439 (0.0435) loss_box_reg: 0.0880 (0.1065) loss_mask: 0.1487 (0.1661) loss_objectness: 0.0017 (0.0022) loss_rpn_box_reg: 0.0053 (0.0071) time: 0.2056 data: 0.0161 max mem: 2772
Epoch: [1] [50/60] eta: 0:00:02 lr: 0.005000 loss: 0.2636 (0.3143) loss_classifier: 0.0314 (0.0417) loss_box_reg: 0.0612 (0.1000) loss_mask: 0.1558 (0.1639) loss_objectness: 0.0013 (0.0021) loss_rpn_box_reg: 0.0043 (0.0065) time: 0.2039 data: 0.0151 max mem: 2772
Epoch: [1] [59/60] eta: 0:00:00 lr: 0.005000 loss: 0.2215 (0.3004) loss_classifier: 0.0314 (0.0407) loss_box_reg: 0.0508 (0.0938) loss_mask: 0.1296 (0.1575) loss_objectness: 0.0009 (0.0020) loss_rpn_box_reg: 0.0033 (0.0063) time: 0.2059 data: 0.0156 max mem: 2772
Epoch: [1] Total time: 0:00:12 (0.2054 s / it)
creating index...
index created!
Test: [ 0/50] eta: 0:00:02 model_time: 0.0416 (0.0416) evaluator_time: 0.0037 (0.0037) time: 0.0579 data: 0.0122 max mem: 2772
Test: [49/50] eta: 0:00:00 model_time: 0.0401 (0.0411) evaluator_time: 0.0030 (0.0041) time: 0.0554 data: 0.0098 max mem: 2772
Test: Total time: 0:00:02 (0.0564 s / it)
Averaged stats: model_time: 0.0401 (0.0411) evaluator_time: 0.0030 (0.0041)
Accumulating evaluation results...
DONE (t=0.01s).
Accumulating evaluation results...
DONE (t=0.01s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.718
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.986
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.924
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.433
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.666
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.731
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.309
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.767
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.767
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.433
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.733
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.779
IoU metric: segm
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.720
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.983
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.887
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.361
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.573
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.738
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.313
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.763
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.763
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.533
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.683
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.778
That's it!
因此,在训练一个周期后,我们获得了 COCO 风格的 mAP > 50,以及 mask mAP 为 65。
但是预测结果是什么样子的呢?让我们从数据集中选取一张图片进行验证。
importmatplotlib.pyplotasplt
fromtorchvision.utilsimport draw_bounding_boxes, draw_segmentation_masks
image = read_image("data/PennFudanPed/PNGImages/FudanPed00046.png")
eval_transform = get_transform(train=False)
model.eval()
with torch.no_grad():
x = eval_transform(image)
# convert RGBA -> RGB and move to device
x = x[:3, ...].to(device)
predictions = model([x, ])
pred = predictions[0]
image = (255.0 * (image - image.min()) / (image.max() - image.min())).to(torch.uint8)
image = image[:3, ...]
pred_labels = [f"pedestrian: {score:.3f}" for label, score in zip(pred["labels"], pred["scores"])]
pred_boxes = pred["boxes"].long()
output_image = draw_bounding_boxes(image, pred_boxes, pred_labels, colors="red")
masks = (pred["masks"] > 0.7).squeeze(1)
output_image = draw_segmentation_masks(output_image, masks, alpha=0.5, colors="blue")
plt.figure(figsize=(12, 12))
plt.imshow(output_image.permute(1, 2, 0))

<matplotlib.image.AxesImage object at 0x7f993ad49840>
结果看起来不错!
总结
在本教程中,您已经学习了如何为自定义数据集上的目标检测模型创建自己的训练管道。为此,您编写了一个返回图像、真实框和分割掩码的 torch.utils.data.Dataset 类。您还利用了一个在 COCO train2017 上预训练的 Mask R-CNN 模型,以便在这个新数据集上进行迁移学习。
有关更完整的示例,包括多机器/多 GPU 训练,请查看 torchvision 仓库中的 references/detection/train.py。