DCGAN 教程
作者: Nathan Inkawhich
简介
本教程将通过一个示例来介绍 DCGANs。我们将训练一个生成对抗网络(GAN),在展示给它许多真实名人的图片后,让它生成新的名人图像。这里的大部分代码来自 pytorch/examples 中的 DCGAN 实现,本文将对该实现进行详细解释,并阐明该模型的工作原理及其背后的原因。不过不用担心,即使没有 GAN 的先验知识,您也可以理解,但对于初学者来说,可能需要花一些时间来理解底层实际发生的事情。此外,为了节省时间,建议使用一块或两块 GPU。让我们从头开始。
生成对抗网络
什么是 GAN?
GANs(生成对抗网络)是一种框架,用于教导深度学习模型捕捉训练数据的分布,从而可以从相同的分布中生成新的数据。GANs 由 Ian Goodfellow 在 2014 年发明,并首次在论文 Generative Adversarial Nets 中描述。它由两个不同的模型组成:生成器 和 判别器。生成器的任务是生成与训练图像相似的“假”图像,而判别器的任务是查看图像并判断它是来自训练数据的真实图像还是生成器生成的假图像。在训练过程中,生成器不断尝试通过生成越来越逼真的假图像来“欺骗”判别器,而判别器则努力成为更好的“侦探”,准确分类真实图像和假图像。这种博弈的平衡点在于,当生成器生成与训练数据几乎无法区分的完美假图像时,判别器将只能以 50% 的置信度猜测生成器的输出是真实还是假图像。
现在,让我们从判别器开始,定义一些在本教程中使用的符号。设 \(x\) 为表示图像的数据。\(D(x)\) 是判别器网络,它输出 \(x\) 来自训练数据而非生成器的(标量)概率。在这里,由于我们处理的是图像,\(D(x)\) 的输入是一个大小为 3x64x64 的 CHW 图像。直观上,当 \(x\) 来自训练数据时,\(D(x)\) 应该为高值;当 \(x\) 来自生成器时,\(D(x)\) 应该为低值。\(D(x)\) 也可以被视为传统的二分类器。
在生成器的表示中,设 \(z\) 为从标准正态分布中采样的潜在空间向量。\(G(z)\) 表示生成器函数,它将潜在向量 \(z\) 映射到数据空间。\(G\) 的目标是估计训练数据所来自的分布 (\(p_{data}\)),以便它可以从该估计的分布 (\(p_g\)) 中生成假样本。
因此,\(D(G(z))\) 表示生成器 \(G\) 的输出为真实图像的概率(标量)。正如 Goodfellow 的论文 中所述,\(D\) 和 \(G\) 在进行一个极小极大博弈,其中 \(D\) 试图最大化其正确分类真实样本和假样本的概率 (\(logD(x)\)),而 \(G\) 试图最小化 \(D\) 将其输出预测为假的概率 (\(log(1-D(G(z)))\))。根据论文,GAN 的损失函数为
[\underset{G}{\text{min}} \underset{D}{\text{max}}V(D,G) = \mathbb{E}_{x\sim p_{data}(x)}\big[logD(x)\big] + \mathbb{E}_{z\sim p_{z}(z)}\big[log(1-D(G(z)))\big] ]
理论上,这个极小极大问题的解出现在 \(p_g = p_{data}\) 时,此时判别器会随机猜测输入是真实的还是伪造的。然而,GAN 的收敛理论仍在积极研究中,实际上模型并不总能训练到这个点。
什么是DCGAN?
DCGAN 是上述 GAN 的直接扩展,不同之处在于它分别在判别器和生成器中显式使用了卷积层和转置卷积层。它最早由 Radford 等人在论文 Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks 中提出。判别器由步幅卷积层、批量归一化层和 LeakyReLU 激活函数组成。输入是一个 3x64x64 的图像,输出是一个标量概率,表示输入是否来自真实数据分布。生成器由转置卷积层、批量归一化层和 ReLU 激活函数组成。输入是从标准正态分布中抽取的潜在向量 (z),输出是一个 3x64x64 的 RGB 图像。步幅转置卷积层允许将潜在向量转换为与图像形状相同的体积。在论文中,作者还提供了一些关于如何设置优化器、如何计算损失函数以及如何初始化模型权重的建议,这些内容将在接下来的部分中详细解释。
#%matplotlib inline
importargparse
importos
importrandom
importtorch
importtorch.nnasnn
importtorch.nn.parallel
importtorch.optimasoptim
importtorch.utils.data
importtorchvision.datasetsasdset
importtorchvision.transformsastransforms
importtorchvision.utilsasvutils
importnumpyasnp
importmatplotlib.pyplotasplt
importmatplotlib.animationasanimation
fromIPython.displayimport HTML
# Set random seed for reproducibility
manualSeed = 999
#manualSeed = random.randint(1, 10000) # use if you want new results
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
torch.use_deterministic_algorithms(True) # Needed for reproducible results
Random Seed: 999
输入
让我们为运行定义一些输入:
-
dataroot- 数据集文件夹根目录的路径。我们将在下一节中详细讨论数据集。 -
workers- 用于通过DataLoader加载数据的工作线程数。 -
batch_size- 训练时使用的批量大小。DCGAN 论文中使用了 128 的批量大小。 -
image_size- 用于训练的图像的空间大小。本实现默认大小为 64x64。如果需要其他大小,必须更改 D 和 G 的结构。更多细节请参见这里。 -
nc- 输入图像中的颜色通道数。对于彩色图像,该值为 3。 -
nz- 潜在向量的长度。 -
ngf- 与生成器中特征图的深度相关。 -
ndf- 设置判别器中传播的特征图的深度。 -
num_epochs- 运行的训练周期数。训练时间越长,结果可能会越好,但所需时间也会更长。 -
lr- 训练的学习率。如 DCGAN 论文所述,该值应为 0.0002。 -
beta1- Adam 优化器的 beta1 超参数。如论文所述,该值应为 0.5。 -
ngpu- 可用的 GPU 数量。如果该值为 0,代码将在 CPU 模式下运行。如果该值大于 0,则将在相应数量的 GPU 上运行。
# Root directory for dataset
dataroot = "data/celeba"
# Number of workers for dataloader
workers = 2
# Batch size during training
batch_size = 128
# Spatial size of training images. All images will be resized to this
# size using a transformer.
image_size = 64
# Number of channels in the training images. For color images this is 3
nc = 3
# Size of z latent vector (i.e. size of generator input)
nz = 100
# Size of feature maps in generator
ngf = 64
# Size of feature maps in discriminator
ndf = 64
# Number of training epochs
num_epochs = 5
# Learning rate for optimizers
lr = 0.0002
# Beta1 hyperparameter for Adam optimizers
beta1 = 0.5
# Number of GPUs available. Use 0 for CPU mode.
ngpu = 1
数据
在本教程中,我们将使用 Celeb-A 面部数据集,该数据集可以从链接的网站或 Google Drive 下载。下载后的文件名为 img_align_celeba.zip。下载完成后,创建一个名为 celeba 的目录,并将 zip 文件解压到该目录中。然后,将本笔记本的 dataroot 输入设置为您刚刚创建的 celeba 目录。最终的目录结构应为:
/path/to/celeba
*>img_align_celeba
*>188242.jpg
*>173822.jpg
*>284702.jpg
*>537394.jpg
...
这是一个重要的步骤,因为我们将使用 ImageFolder 数据集类,它要求数据集根文件夹中存在子目录。现在,我们可以创建数据集、创建数据加载器、设置运行的设备,并最终可视化一些训练数据。
# We can use an image folder dataset the way we have it setup.
# Create the dataset
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# Create the dataloader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# Plot some training images
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))
plt.show()

实现
在设置好输入参数并准备好数据集后,我们现在可以进入实现部分。我们将从权重初始化策略开始,然后详细讨论生成器、判别器、损失函数以及训练循环。
权重初始化
根据 DCGAN 论文,作者明确指出所有模型权重应从均值为 0、标准差为 0.02 的正态分布中随机初始化。weights_init 函数接收一个已初始化的模型作为输入,并重新初始化所有卷积层、转置卷积层和批量归一化层,以满足这一要求。该函数在模型初始化后立即应用。
# custom weights initialization called on ``netG`` and ``netD``
defweights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
生成器
生成器 \(G\) 被设计为将潜在空间向量 \(z\) 映射到数据空间。由于我们的数据是图像,将 \(z\) 转换为数据空间意味着最终生成一个与训练图像大小相同的 RGB 图像(即 3x64x64)。在实际操作中,这是通过一系列步幅为 2 的二维转置卷积层实现的,每一层都配有一个 2D 批归一化层和一个 ReLU 激活函数。生成器的输出通过 tanh 函数处理,以将其返回到输入数据的范围 \([-1,1]\)。值得注意的是,转置卷积层之后的批归一化函数的存在,这是 DCGAN 论文的一个重要贡献。这些层有助于训练期间梯度的流动。下图展示了 DCGAN 论文中生成器的结构。

请注意,我们在输入部分设置的参数(nz、ngf 和 nc)如何影响代码中的生成器架构。nz 是 z 输入向量的长度,ngf 与生成器中传播的特征图的大小相关,而 nc 是输出图像中的通道数(对于 RGB 图像设置为 3)。以下是生成器的代码。
# Generator Code
classGenerator(nn.Module):
def__init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. ``(ngf*8) x 4 x 4``
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. ``(ngf*4) x 8 x 8``
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. ``(ngf*2) x 16 x 16``
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. ``(ngf) x 32 x 32``
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. ``(nc) x 64 x 64``
)
defforward(self, input):
return self.main(input)
现在,我们可以实例化生成器并应用 weights_init 函数。查看打印出的模型以了解生成器对象的结构。
# Create the generator
netG = Generator(ngpu).to(device)
# Handle multi-GPU if desired
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
# Apply the ``weights_init`` function to randomly initialize all weights
# to ``mean=0``, ``stdev=0.02``.
netG.apply(weights_init)
# Print the model
print(netG)
Generator(
(main): Sequential(
(0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)
鉴别器
如前所述,判别器 \(D\) 是一个二分类网络,它以图像作为输入,并输出一个标量概率,表示输入图像是真实的(而非伪造的)。在这里,\(D\) 接受一个 3x64x64 的输入图像,通过一系列 Conv2d、BatchNorm2d 和 LeakyReLU 层进行处理,并通过 Sigmoid 激活函数输出最终概率。如果需要,可以为此问题扩展更多层,但使用步幅卷积(strided convolution)、批归一化(BatchNorm)和 LeakyReLU 有其重要意义。DCGAN 论文提到,使用步幅卷积而非池化来进行下采样是一个良好的实践,因为这可以让网络学习自己的池化函数。此外,批归一化和 LeakyReLU 函数有助于促进健康的梯度流动,这对于 \(G\) 和 \(D\) 的学习过程至关重要。
判别器代码
classDiscriminator(nn.Module):
def__init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is ``(nc) x 64 x 64``
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf) x 32 x 32``
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf*2) x 16 x 16``
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf*4) x 8 x 8``
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf*8) x 4 x 4``
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
defforward(self, input):
return self.main(input)
现在,就像生成器一样,我们可以创建判别器,应用 weights_init 函数,并打印模型的结构。
# Create the Discriminator
netD = Discriminator(ngpu).to(device)
# Handle multi-GPU if desired
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
# Apply the ``weights_init`` function to randomly initialize all weights
# like this: ``to mean=0, stdev=0.2``.
netD.apply(weights_init)
# Print the model
print(netD)
Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(12): Sigmoid()
)
)
损失函数与优化器
在设置好 \(D\) 和 \(G\) 之后,我们可以通过损失函数和优化器来指定它们的学习方式。我们将使用 PyTorch 中定义的二元交叉熵损失函数(BCELoss):
\[\ell(x, y) = L = \{l_1,\dots,l_N\}^\top, \quad l_n = - \left[ y_n \cdot \log x_n + (1 - y_n) \cdot \log (1 - x_n) \right] \]
请注意,此函数提供了目标函数中两个对数分量的计算(即 \(log(D(x))\) 和 \(log(1-D(G(z)))\))。我们可以通过 \(y\) 输入来指定使用 BCE 方程的哪一部分。这将在稍后的训练循环中实现,但重要的是要理解我们如何通过改变 \(y\)(即 GT 标签)来选择希望计算的分量。
接下来,我们将真实标签定义为 1,将伪造标签定义为 0。这些标签将用于计算 \(D\) 和 \(G\) 的损失,这也是原始 GAN 论文中使用的惯例。最后,我们设置了两个独立的优化器,一个用于 \(D\),另一个用于 \(G\)。按照 DCGAN 论文中的说明,两者都是 Adam 优化器,学习率为 0.0002,Beta1 = 0.5。为了跟踪生成器的学习进展,我们将生成一批从高斯分布中提取的固定潜在向量(即 fixed_noise)。在训练循环中,我们会定期将此 fixed_noise 输入到 \(G\) 中,并在迭代过程中看到图像从噪声中逐渐形成。
# Initialize the ``BCELoss`` function
criterion = nn.BCELoss()
# Create batch of latent vectors that we will use to visualize
# the progression of the generator
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
# Establish convention for real and fake labels during training
real_label = 1.
fake_label = 0.
# Setup Adam optimizers for both G and D
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
训练
最后,既然我们已经定义了 GAN 框架的所有部分,就可以开始训练了。需要注意的是,训练 GAN 有点像一门艺术,因为错误的超参数设置会导致模式崩溃,而且很难解释出错的原因。在这里,我们将严格遵循 Goodfellow 论文中的算法 1,同时遵循 ganhacks 中展示的一些最佳实践。具体来说,我们将“为真实图像和生成图像构建不同的 mini-batch”,并将 G 的目标函数调整为最大化 \(log(D(G(z)))\)。训练主要分为两部分:第 1 部分更新判别器,第 2 部分更新生成器。
第一部分 - 训练判别器
回想一下,训练判别器的目标是最大化正确分类给定输入为真实或伪造的概率。用Goodfellow的话来说,我们希望“通过上升其随机梯度来更新判别器”。实际上,我们希望最大化 \(log(D(x)) + log(1-D(G(z)))\)。根据ganhacks的独立小批量建议,我们将分两步计算。首先,我们将从训练集中构建一批真实样本,通过 \(D\) 进行前向传递,计算损失 (\(log(D(x))\)),然后在反向传递中计算梯度。其次,我们将使用当前生成器构建一批伪造样本,通过 \(D\) 进行前向传递,计算损失 (\(log(1-D(G(z)))\)),并在反向传递中累积梯度。现在,通过从全真实样本和全伪造样本中累积的梯度,我们调用判别器优化器的一步。
第二部分 - 训练生成器
正如原论文所述,我们希望通过最小化 \(log(1-D(G(z)))\) 来训练生成器,以生成更好的假样本。然而,Goodfellow 指出,这种方法在训练初期无法提供足够的梯度。为了解决这个问题,我们改为最大化 \(log(D(G(z)))\)。在代码中,我们通过以下步骤实现这一目标:使用判别器对第一部分中生成器的输出进行分类,使用真实标签作为 Ground Truth 计算生成器的损失,在反向传播中计算生成器的梯度,最后通过优化器更新生成器的参数。虽然使用真实标签作为损失函数的 Ground Truth 可能看起来有些反直觉,但这使得我们可以利用 BCELoss 中的 \(log(x)\) 部分(而不是 \(log(1-x)\) 部分),而这正是我们想要的。
最后,我们将进行一些统计报告,并在每个 epoch 结束时,将固定的噪声批次通过生成器推送,以直观地跟踪生成器(G)的训练进展。报告的训练统计信息包括:
-
Loss_D - 判别器损失,计算为所有真实批次和所有虚假批次的损失之和(\(log(D(x)) + log(1 - D(G(z)))\))。
-
Loss_G - 生成器损失,计算为 \(log(D(G(z)))\)。
-
D(x) - 判别器对所有真实批次的平均输出(跨批次)。这应该开始时接近 1,然后在 G 变得更优时理论上收敛到 0.5。思考一下为什么会这样。
-
D(G(z)) - 判别器对所有虚假批次的平均输出。第一个数字是在 D 更新之前,第二个数字是在 D 更新之后。这些数字应该开始时接近 0,并在 G 变得更优时收敛到 0.5。思考一下为什么会这样。
注意: 此步骤可能需要一些时间,具体取决于您运行的 epoch 数量以及是否从数据集中删除了一些数据。
# Training Loop
# Lists to keep track of progress
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
# For each epoch
for epoch in range(num_epochs):
# For each batch in the dataloader
for i, data in enumerate(dataloader, 0):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
###########################
## Train with all-real batch
netD.zero_grad()
# Format batch
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=device)
# Forward pass real batch through D
output = netD(real_cpu).view(-1)
# Calculate loss on all-real batch
errD_real = criterion(output, label)
# Calculate gradients for D in backward pass
errD_real.backward()
D_x = output.mean().item()
## Train with all-fake batch
# Generate batch of latent vectors
noise = torch.randn(b_size, nz, 1, 1, device=device)
# Generate fake image batch with G
fake = netG(noise)
label.fill_(fake_label)
# Classify all fake batch with D
output = netD(fake.detach()).view(-1)
# Calculate D's loss on the all-fake batch
errD_fake = criterion(output, label)
# Calculate the gradients for this batch, accumulated (summed) with previous gradients
errD_fake.backward()
D_G_z1 = output.mean().item()
# Compute error of D as sum over the fake and the real batches
errD = errD_real + errD_fake
# Update D
optimizerD.step()
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
netG.zero_grad()
label.fill_(real_label) # fake labels are real for generator cost
# Since we just updated D, perform another forward pass of all-fake batch through D
output = netD(fake).view(-1)
# Calculate G's loss based on this output
errG = criterion(output, label)
# Calculate gradients for G
errG.backward()
D_G_z2 = output.mean().item()
# Update G
optimizerG.step()
# Output training stats
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# Save Losses for plotting later
G_losses.append(errG.item())
D_losses.append(errD.item())
# Check how the generator is doing by saving G's output on fixed_noise
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
Starting Training Loop...
[0/5][0/1583] Loss_D: 1.4639 Loss_G: 6.9356 D(x): 0.7143 D(G(z)): 0.5877 / 0.0017
[0/5][50/1583] Loss_D: 0.3242 Loss_G: 31.5483 D(x): 0.8383 D(G(z)): 0.0000 / 0.0000
[0/5][100/1583] Loss_D: 0.6255 Loss_G: 4.1696 D(x): 0.7227 D(G(z)): 0.0358 / 0.0356
[0/5][150/1583] Loss_D: 0.2219 Loss_G: 3.3579 D(x): 0.9007 D(G(z)): 0.0666 / 0.0863
[0/5][200/1583] Loss_D: 0.8795 Loss_G: 4.5660 D(x): 0.6613 D(G(z)): 0.2131 / 0.0210
[0/5][250/1583] Loss_D: 0.4980 Loss_G: 3.2480 D(x): 0.7250 D(G(z)): 0.0488 / 0.1019
[0/5][300/1583] Loss_D: 1.6464 Loss_G: 4.2970 D(x): 0.3272 D(G(z)): 0.0047 / 0.0320
[0/5][350/1583] Loss_D: 0.6214 Loss_G: 4.2107 D(x): 0.9090 D(G(z)): 0.3447 / 0.0251
[0/5][400/1583] Loss_D: 0.6713 Loss_G: 4.2897 D(x): 0.9257 D(G(z)): 0.3878 / 0.0294
[0/5][450/1583] Loss_D: 0.5819 Loss_G: 3.9728 D(x): 0.7532 D(G(z)): 0.1509 / 0.0317
[0/5][500/1583] Loss_D: 1.4538 Loss_G: 1.0834 D(x): 0.3934 D(G(z)): 0.1352 / 0.4428
[0/5][550/1583] Loss_D: 0.4030 Loss_G: 4.4588 D(x): 0.8614 D(G(z)): 0.1533 / 0.0207
[0/5][600/1583] Loss_D: 0.6030 Loss_G: 3.2111 D(x): 0.6778 D(G(z)): 0.0695 / 0.0673
[0/5][650/1583] Loss_D: 0.8971 Loss_G: 4.5883 D(x): 0.7796 D(G(z)): 0.3915 / 0.0173
[0/5][700/1583] Loss_D: 0.3551 Loss_G: 5.3014 D(x): 0.8556 D(G(z)): 0.1236 / 0.0085
[0/5][750/1583] Loss_D: 1.1255 Loss_G: 3.2437 D(x): 0.4403 D(G(z)): 0.0122 / 0.0860
[0/5][800/1583] Loss_D: 0.3147 Loss_G: 4.5361 D(x): 0.8490 D(G(z)): 0.1034 / 0.0186
[0/5][850/1583] Loss_D: 0.7247 Loss_G: 2.6568 D(x): 0.6426 D(G(z)): 0.1107 / 0.1354
[0/5][900/1583] Loss_D: 0.2811 Loss_G: 3.4807 D(x): 0.8552 D(G(z)): 0.0830 / 0.0534
[0/5][950/1583] Loss_D: 0.7600 Loss_G: 6.4174 D(x): 0.8989 D(G(z)): 0.3859 / 0.0054
[0/5][1000/1583] Loss_D: 0.3480 Loss_G: 5.2934 D(x): 0.9010 D(G(z)): 0.1750 / 0.0145
[0/5][1050/1583] Loss_D: 0.5616 Loss_G: 5.3993 D(x): 0.7005 D(G(z)): 0.0210 / 0.0139
[0/5][1100/1583] Loss_D: 0.1591 Loss_G: 4.6903 D(x): 0.9135 D(G(z)): 0.0464 / 0.0168
[0/5][1150/1583] Loss_D: 0.3180 Loss_G: 4.7279 D(x): 0.8923 D(G(z)): 0.1549 / 0.0145
[0/5][1200/1583] Loss_D: 0.4964 Loss_G: 4.0195 D(x): 0.8374 D(G(z)): 0.2212 / 0.0322
[0/5][1250/1583] Loss_D: 1.0099 Loss_G: 6.1041 D(x): 0.9504 D(G(z)): 0.5440 / 0.0055
[0/5][1300/1583] Loss_D: 0.4111 Loss_G: 5.3166 D(x): 0.8679 D(G(z)): 0.1921 / 0.0089
[0/5][1350/1583] Loss_D: 1.8342 Loss_G: 1.6638 D(x): 0.2817 D(G(z)): 0.0134 / 0.2739
[0/5][1400/1583] Loss_D: 0.4436 Loss_G: 4.5273 D(x): 0.8271 D(G(z)): 0.1715 / 0.0195
[0/5][1450/1583] Loss_D: 0.9782 Loss_G: 2.6528 D(x): 0.4883 D(G(z)): 0.0166 / 0.1239
[0/5][1500/1583] Loss_D: 0.6928 Loss_G: 3.2443 D(x): 0.6108 D(G(z)): 0.0365 / 0.0691
[0/5][1550/1583] Loss_D: 0.4835 Loss_G: 4.4397 D(x): 0.8843 D(G(z)): 0.2668 / 0.0192
[1/5][0/1583] Loss_D: 0.6268 Loss_G: 4.9622 D(x): 0.9252 D(G(z)): 0.3613 / 0.0135
[1/5][50/1583] Loss_D: 0.7514 Loss_G: 0.7346 D(x): 0.5730 D(G(z)): 0.0373 / 0.5340
[1/5][100/1583] Loss_D: 0.4567 Loss_G: 3.0858 D(x): 0.7565 D(G(z)): 0.1009 / 0.0716
[1/5][150/1583] Loss_D: 0.5032 Loss_G: 3.5198 D(x): 0.7965 D(G(z)): 0.1911 / 0.0456
[1/5][200/1583] Loss_D: 0.5624 Loss_G: 3.2230 D(x): 0.8774 D(G(z)): 0.3011 / 0.0633
[1/5][250/1583] Loss_D: 1.1976 Loss_G: 1.7349 D(x): 0.4448 D(G(z)): 0.0122 / 0.2734
[1/5][300/1583] Loss_D: 0.5653 Loss_G: 4.2695 D(x): 0.8712 D(G(z)): 0.2859 / 0.0234
[1/5][350/1583] Loss_D: 2.1271 Loss_G: 2.1558 D(x): 0.1991 D(G(z)): 0.0065 / 0.1695
[1/5][400/1583] Loss_D: 0.3964 Loss_G: 3.1797 D(x): 0.7650 D(G(z)): 0.0825 / 0.0578
[1/5][450/1583] Loss_D: 0.4872 Loss_G: 4.7998 D(x): 0.9149 D(G(z)): 0.2904 / 0.0139
[1/5][500/1583] Loss_D: 0.3336 Loss_G: 3.4355 D(x): 0.8826 D(G(z)): 0.1566 / 0.0517
[1/5][550/1583] Loss_D: 0.6615 Loss_G: 3.5165 D(x): 0.7637 D(G(z)): 0.2485 / 0.0470
[1/5][600/1583] Loss_D: 0.5524 Loss_G: 2.7687 D(x): 0.6851 D(G(z)): 0.0846 / 0.0946
[1/5][650/1583] Loss_D: 0.5974 Loss_G: 4.2535 D(x): 0.9131 D(G(z)): 0.3298 / 0.0285
[1/5][700/1583] Loss_D: 0.4352 Loss_G: 3.6688 D(x): 0.9428 D(G(z)): 0.2688 / 0.0460
[1/5][750/1583] Loss_D: 0.3833 Loss_G: 2.9862 D(x): 0.8509 D(G(z)): 0.1604 / 0.0680
[1/5][800/1583] Loss_D: 0.5156 Loss_G: 3.0845 D(x): 0.7028 D(G(z)): 0.0994 / 0.0728
[1/5][850/1583] Loss_D: 1.3500 Loss_G: 8.4715 D(x): 0.9820 D(G(z)): 0.6608 / 0.0004
[1/5][900/1583] Loss_D: 0.7279 Loss_G: 5.5268 D(x): 0.8525 D(G(z)): 0.3799 / 0.0087
[1/5][950/1583] Loss_D: 0.5133 Loss_G: 2.6554 D(x): 0.7431 D(G(z)): 0.1307 / 0.0929
[1/5][1000/1583] Loss_D: 0.5413 Loss_G: 4.2976 D(x): 0.8956 D(G(z)): 0.3027 / 0.0233
[1/5][1050/1583] Loss_D: 0.6781 Loss_G: 1.9833 D(x): 0.6030 D(G(z)): 0.0238 / 0.2025
[1/5][1100/1583] Loss_D: 0.4322 Loss_G: 2.6027 D(x): 0.7542 D(G(z)): 0.0740 / 0.1022
[1/5][1150/1583] Loss_D: 1.1863 Loss_G: 5.5669 D(x): 0.9340 D(G(z)): 0.6007 / 0.0069
[1/5][1200/1583] Loss_D: 0.6455 Loss_G: 4.5968 D(x): 0.9106 D(G(z)): 0.3760 / 0.0180
[1/5][1250/1583] Loss_D: 0.7295 Loss_G: 3.1293 D(x): 0.7430 D(G(z)): 0.2787 / 0.0727
[1/5][1300/1583] Loss_D: 1.0030 Loss_G: 1.7375 D(x): 0.4721 D(G(z)): 0.0533 / 0.2379
[1/5][1350/1583] Loss_D: 1.6538 Loss_G: 5.9430 D(x): 0.9442 D(G(z)): 0.7357 / 0.0052
[1/5][1400/1583] Loss_D: 0.5649 Loss_G: 2.9169 D(x): 0.8183 D(G(z)): 0.2687 / 0.0734
[1/5][1450/1583] Loss_D: 0.4261 Loss_G: 3.0610 D(x): 0.7964 D(G(z)): 0.1375 / 0.0621
[1/5][1500/1583] Loss_D: 0.4946 Loss_G: 3.1410 D(x): 0.8565 D(G(z)): 0.2451 / 0.0738
[1/5][1550/1583] Loss_D: 0.8549 Loss_G: 1.7395 D(x): 0.5435 D(G(z)): 0.0914 / 0.2417
[2/5][0/1583] Loss_D: 0.5623 Loss_G: 2.1095 D(x): 0.6400 D(G(z)): 0.0452 / 0.1684
[2/5][50/1583] Loss_D: 0.5614 Loss_G: 4.2505 D(x): 0.9462 D(G(z)): 0.3607 / 0.0201
[2/5][100/1583] Loss_D: 0.7408 Loss_G: 1.7462 D(x): 0.6195 D(G(z)): 0.1396 / 0.2273
[2/5][150/1583] Loss_D: 0.4944 Loss_G: 2.2602 D(x): 0.7388 D(G(z)): 0.1378 / 0.1415
[2/5][200/1583] Loss_D: 0.6049 Loss_G: 2.6208 D(x): 0.7689 D(G(z)): 0.2524 / 0.0962
[2/5][250/1583] Loss_D: 0.5664 Loss_G: 2.9909 D(x): 0.8120 D(G(z)): 0.2578 / 0.0660
[2/5][300/1583] Loss_D: 0.5038 Loss_G: 3.4062 D(x): 0.8648 D(G(z)): 0.2613 / 0.0484
[2/5][350/1583] Loss_D: 0.5945 Loss_G: 1.9982 D(x): 0.7523 D(G(z)): 0.2242 / 0.1662
[2/5][400/1583] Loss_D: 1.1467 Loss_G: 4.7130 D(x): 0.8820 D(G(z)): 0.5668 / 0.0155
[2/5][450/1583] Loss_D: 0.6520 Loss_G: 3.4336 D(x): 0.9213 D(G(z)): 0.4030 / 0.0441
[2/5][500/1583] Loss_D: 0.8613 Loss_G: 1.0815 D(x): 0.5288 D(G(z)): 0.0760 / 0.3905
[2/5][550/1583] Loss_D: 0.6906 Loss_G: 4.1047 D(x): 0.8655 D(G(z)): 0.3697 / 0.0280
[2/5][600/1583] Loss_D: 0.5654 Loss_G: 1.9830 D(x): 0.6963 D(G(z)): 0.1304 / 0.1729
[2/5][650/1583] Loss_D: 0.6044 Loss_G: 1.8089 D(x): 0.7001 D(G(z)): 0.1727 / 0.2082
[2/5][700/1583] Loss_D: 0.6106 Loss_G: 1.6630 D(x): 0.6461 D(G(z)): 0.0877 / 0.2441
[2/5][750/1583] Loss_D: 1.0203 Loss_G: 1.3345 D(x): 0.5085 D(G(z)): 0.1785 / 0.3240
[2/5][800/1583] Loss_D: 0.5377 Loss_G: 2.5538 D(x): 0.7565 D(G(z)): 0.1961 / 0.1027
[2/5][850/1583] Loss_D: 0.3789 Loss_G: 3.0581 D(x): 0.8850 D(G(z)): 0.2092 / 0.0621
[2/5][900/1583] Loss_D: 1.3570 Loss_G: 4.9757 D(x): 0.9622 D(G(z)): 0.6302 / 0.0141
[2/5][950/1583] Loss_D: 0.6596 Loss_G: 2.4686 D(x): 0.7542 D(G(z)): 0.2721 / 0.1085
[2/5][1000/1583] Loss_D: 0.6875 Loss_G: 1.4414 D(x): 0.6144 D(G(z)): 0.1249 / 0.2787
[2/5][1050/1583] Loss_D: 0.4792 Loss_G: 2.6635 D(x): 0.7570 D(G(z)): 0.1479 / 0.0962
[2/5][1100/1583] Loss_D: 1.0462 Loss_G: 4.0517 D(x): 0.8556 D(G(z)): 0.5220 / 0.0298
[2/5][1150/1583] Loss_D: 0.5255 Loss_G: 2.5377 D(x): 0.8195 D(G(z)): 0.2469 / 0.0990
[2/5][1200/1583] Loss_D: 0.4260 Loss_G: 3.4207 D(x): 0.9237 D(G(z)): 0.2649 / 0.0436
[2/5][1250/1583] Loss_D: 0.4721 Loss_G: 2.3755 D(x): 0.7558 D(G(z)): 0.1434 / 0.1175
[2/5][1300/1583] Loss_D: 1.0240 Loss_G: 4.2717 D(x): 0.8719 D(G(z)): 0.5166 / 0.0230
[2/5][1350/1583] Loss_D: 0.5882 Loss_G: 1.7832 D(x): 0.7439 D(G(z)): 0.2153 / 0.2073
[2/5][1400/1583] Loss_D: 0.6932 Loss_G: 3.7904 D(x): 0.9076 D(G(z)): 0.4070 / 0.0330
[2/5][1450/1583] Loss_D: 0.8912 Loss_G: 4.0172 D(x): 0.8996 D(G(z)): 0.4849 / 0.0256
[2/5][1500/1583] Loss_D: 0.7962 Loss_G: 4.5561 D(x): 0.9384 D(G(z)): 0.4720 / 0.0171
[2/5][1550/1583] Loss_D: 0.7970 Loss_G: 4.4968 D(x): 0.9568 D(G(z)): 0.4803 / 0.0177
[3/5][0/1583] Loss_D: 0.6207 Loss_G: 1.9942 D(x): 0.6708 D(G(z)): 0.1338 / 0.1703
[3/5][50/1583] Loss_D: 0.8271 Loss_G: 0.8199 D(x): 0.5310 D(G(z)): 0.0875 / 0.4851
[3/5][100/1583] Loss_D: 0.4647 Loss_G: 2.4834 D(x): 0.7816 D(G(z)): 0.1693 / 0.1163
[3/5][150/1583] Loss_D: 0.4473 Loss_G: 2.5716 D(x): 0.8176 D(G(z)): 0.1905 / 0.1006
[3/5][200/1583] Loss_D: 0.6719 Loss_G: 3.3996 D(x): 0.8535 D(G(z)): 0.3625 / 0.0451
[3/5][250/1583] Loss_D: 0.4477 Loss_G: 2.9992 D(x): 0.8987 D(G(z)): 0.2639 / 0.0669
[3/5][300/1583] Loss_D: 0.8086 Loss_G: 1.4259 D(x): 0.6547 D(G(z)): 0.2408 / 0.2925
[3/5][350/1583] Loss_D: 0.5199 Loss_G: 1.9725 D(x): 0.8318 D(G(z)): 0.2539 / 0.1746
[3/5][400/1583] Loss_D: 0.5976 Loss_G: 1.6428 D(x): 0.6476 D(G(z)): 0.1018 / 0.2381
[3/5][450/1583] Loss_D: 0.6942 Loss_G: 3.5290 D(x): 0.8904 D(G(z)): 0.3982 / 0.0395
[3/5][500/1583] Loss_D: 1.1736 Loss_G: 0.7940 D(x): 0.4196 D(G(z)): 0.0627 / 0.4958
[3/5][550/1583] Loss_D: 0.6200 Loss_G: 2.4844 D(x): 0.8689 D(G(z)): 0.3360 / 0.1066
[3/5][600/1583] Loss_D: 0.9227 Loss_G: 1.6358 D(x): 0.5063 D(G(z)): 0.1036 / 0.2437
[3/5][650/1583] Loss_D: 0.5858 Loss_G: 3.6943 D(x): 0.8388 D(G(z)): 0.3057 / 0.0372
[3/5][700/1583] Loss_D: 0.6033 Loss_G: 2.0149 D(x): 0.7311 D(G(z)): 0.1964 / 0.1781
[3/5][750/1583] Loss_D: 0.5502 Loss_G: 3.1818 D(x): 0.8601 D(G(z)): 0.3002 / 0.0541
[3/5][800/1583] Loss_D: 0.6964 Loss_G: 3.9791 D(x): 0.8740 D(G(z)): 0.3934 / 0.0255
[3/5][850/1583] Loss_D: 1.3287 Loss_G: 1.1903 D(x): 0.3969 D(G(z)): 0.1147 / 0.3856
[3/5][900/1583] Loss_D: 0.6994 Loss_G: 3.3330 D(x): 0.8640 D(G(z)): 0.3838 / 0.0500
[3/5][950/1583] Loss_D: 0.8296 Loss_G: 0.9049 D(x): 0.5234 D(G(z)): 0.0647 / 0.4408
[3/5][1000/1583] Loss_D: 1.0949 Loss_G: 0.7958 D(x): 0.4138 D(G(z)): 0.0365 / 0.4985
[3/5][1050/1583] Loss_D: 0.6095 Loss_G: 2.4836 D(x): 0.7916 D(G(z)): 0.2766 / 0.1107
[3/5][1100/1583] Loss_D: 0.4538 Loss_G: 2.0659 D(x): 0.7611 D(G(z)): 0.1358 / 0.1586
[3/5][1150/1583] Loss_D: 0.6258 Loss_G: 2.2310 D(x): 0.6639 D(G(z)): 0.1423 / 0.1486
[3/5][1200/1583] Loss_D: 0.5801 Loss_G: 1.4977 D(x): 0.6810 D(G(z)): 0.1214 / 0.2645
[3/5][1250/1583] Loss_D: 2.3328 Loss_G: 4.3672 D(x): 0.9818 D(G(z)): 0.8527 / 0.0235
[3/5][1300/1583] Loss_D: 0.5145 Loss_G: 2.7098 D(x): 0.8002 D(G(z)): 0.2147 / 0.0871
[3/5][1350/1583] Loss_D: 0.7088 Loss_G: 0.9405 D(x): 0.6495 D(G(z)): 0.1748 / 0.4374
[3/5][1400/1583] Loss_D: 0.9545 Loss_G: 1.3225 D(x): 0.5137 D(G(z)): 0.1441 / 0.3294
[3/5][1450/1583] Loss_D: 0.5780 Loss_G: 1.8844 D(x): 0.7241 D(G(z)): 0.1891 / 0.1926
[3/5][1500/1583] Loss_D: 0.5709 Loss_G: 1.8434 D(x): 0.7404 D(G(z)): 0.1949 / 0.2120
[3/5][1550/1583] Loss_D: 0.5434 Loss_G: 2.0119 D(x): 0.7713 D(G(z)): 0.2165 / 0.1718
[4/5][0/1583] Loss_D: 0.4163 Loss_G: 2.6372 D(x): 0.8265 D(G(z)): 0.1795 / 0.0943
[4/5][50/1583] Loss_D: 0.6529 Loss_G: 2.0663 D(x): 0.7036 D(G(z)): 0.2107 / 0.1570
[4/5][100/1583] Loss_D: 0.7297 Loss_G: 1.5304 D(x): 0.5676 D(G(z)): 0.0706 / 0.2603
[4/5][150/1583] Loss_D: 0.6044 Loss_G: 1.5723 D(x): 0.6480 D(G(z)): 0.0917 / 0.2653
[4/5][200/1583] Loss_D: 0.8838 Loss_G: 3.6003 D(x): 0.8782 D(G(z)): 0.4936 / 0.0406
[4/5][250/1583] Loss_D: 0.6898 Loss_G: 3.9428 D(x): 0.8996 D(G(z)): 0.3995 / 0.0281
[4/5][300/1583] Loss_D: 0.6976 Loss_G: 1.6595 D(x): 0.6783 D(G(z)): 0.2150 / 0.2308
[4/5][350/1583] Loss_D: 1.3657 Loss_G: 5.0456 D(x): 0.9590 D(G(z)): 0.6777 / 0.0097
[4/5][400/1583] Loss_D: 0.6273 Loss_G: 1.8805 D(x): 0.6428 D(G(z)): 0.1129 / 0.1901
[4/5][450/1583] Loss_D: 0.5668 Loss_G: 2.2586 D(x): 0.7622 D(G(z)): 0.2226 / 0.1269
[4/5][500/1583] Loss_D: 0.5272 Loss_G: 2.0144 D(x): 0.7180 D(G(z)): 0.1372 / 0.1623
[4/5][550/1583] Loss_D: 2.2434 Loss_G: 5.3635 D(x): 0.9622 D(G(z)): 0.8132 / 0.0124
[4/5][600/1583] Loss_D: 1.2922 Loss_G: 5.5550 D(x): 0.9562 D(G(z)): 0.6563 / 0.0061
[4/5][650/1583] Loss_D: 0.5544 Loss_G: 2.2016 D(x): 0.8119 D(G(z)): 0.2580 / 0.1429
[4/5][700/1583] Loss_D: 0.4944 Loss_G: 1.9504 D(x): 0.7448 D(G(z)): 0.1440 / 0.1755
[4/5][750/1583] Loss_D: 0.4139 Loss_G: 2.3911 D(x): 0.8139 D(G(z)): 0.1624 / 0.1218
[4/5][800/1583] Loss_D: 0.7332 Loss_G: 1.7267 D(x): 0.6219 D(G(z)): 0.1537 / 0.2255
[4/5][850/1583] Loss_D: 0.6277 Loss_G: 1.9473 D(x): 0.6935 D(G(z)): 0.1791 / 0.1803
[4/5][900/1583] Loss_D: 0.7917 Loss_G: 3.7302 D(x): 0.9017 D(G(z)): 0.4523 / 0.0328
[4/5][950/1583] Loss_D: 0.5253 Loss_G: 2.1947 D(x): 0.7346 D(G(z)): 0.1590 / 0.1411
[4/5][1000/1583] Loss_D: 1.1477 Loss_G: 4.9436 D(x): 0.9429 D(G(z)): 0.6048 / 0.0121
[4/5][1050/1583] Loss_D: 0.6783 Loss_G: 4.0750 D(x): 0.8798 D(G(z)): 0.3849 / 0.0225
[4/5][1100/1583] Loss_D: 0.6448 Loss_G: 2.5082 D(x): 0.6359 D(G(z)): 0.0836 / 0.1189
[4/5][1150/1583] Loss_D: 0.9304 Loss_G: 0.6922 D(x): 0.4841 D(G(z)): 0.0729 / 0.5382
[4/5][1200/1583] Loss_D: 0.5627 Loss_G: 4.1992 D(x): 0.9206 D(G(z)): 0.3443 / 0.0217
[4/5][1250/1583] Loss_D: 0.7861 Loss_G: 1.5696 D(x): 0.6637 D(G(z)): 0.2357 / 0.2554
[4/5][1300/1583] Loss_D: 0.6603 Loss_G: 4.2306 D(x): 0.9545 D(G(z)): 0.4271 / 0.0212
[4/5][1350/1583] Loss_D: 0.9006 Loss_G: 1.5437 D(x): 0.5667 D(G(z)): 0.1951 / 0.2718
[4/5][1400/1583] Loss_D: 0.7157 Loss_G: 3.9809 D(x): 0.9339 D(G(z)): 0.4234 / 0.0284
[4/5][1450/1583] Loss_D: 0.9364 Loss_G: 5.0477 D(x): 0.8877 D(G(z)): 0.5022 / 0.0105
[4/5][1500/1583] Loss_D: 0.5947 Loss_G: 1.7611 D(x): 0.7653 D(G(z)): 0.2372 / 0.2149
[4/5][1550/1583] Loss_D: 1.4834 Loss_G: 0.6801 D(x): 0.3084 D(G(z)): 0.0380 / 0.5589
结果
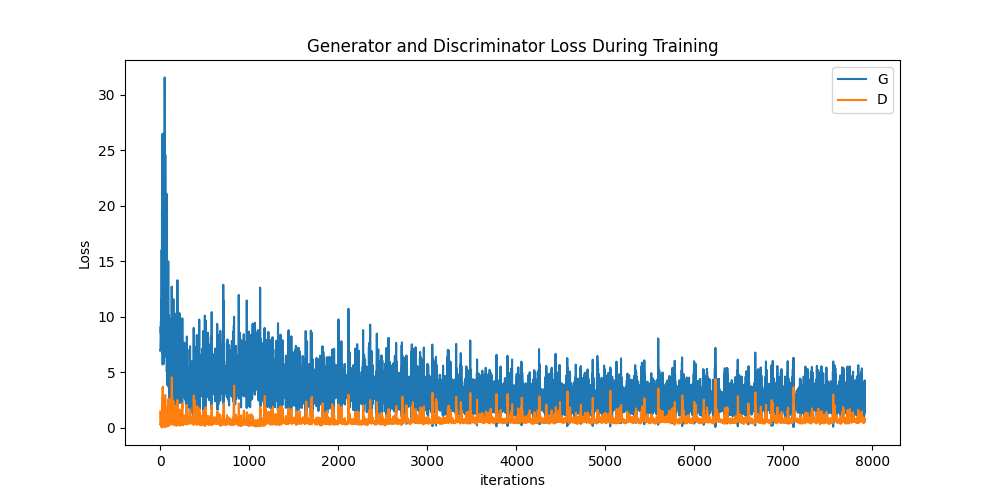
最后,让我们来看看结果如何。这里,我们将查看三种不同的结果。首先,我们将观察 D 和 G 的损失在训练过程中的变化。其次,我们将可视化 G 在固定噪声批次上每个 epoch 的输出。第三,我们将对比一批真实数据与 G 生成的一批假数据。
损失与训练迭代
下图是 D 和 G 的损失随训练迭代的变化图。
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
G 生成器的训练过程可视化
还记得我们是如何在每个训练周期结束后保存生成器在固定噪声批次上的输出吗?现在,我们可以通过动画来可视化 G 的训练过程。按下播放按钮即可开始动画。
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())

真实图像 vs. 生成图像
最后,让我们将一些真实图像和生成图像进行对比。
# Grab a batch of real images from the dataloader
real_batch = next(iter(dataloader))
# Plot the real images
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# Plot the fake images from the last epoch
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()

下一步该做什么
我们已经到达了旅程的终点,但您还可以从这里出发前往以下几个方向:您可以: