Elastic Agent
服务器
弹性代理是torchelastic的控制组件。
这是一个启动并管理底层工作进程的程序。代理负责:
-
在使用分布式 torch 时,启动 worker 会自动提供所有必需的信息,使得调用
torch.distributed.init_process_group()变得简单且顺利。 -
容错性:监控工作进程,一旦发现工作进程出现故障或状态不佳,将重启所有进程。
-
弹性:能够响应成员的变化,并使用新的成员列表来重启工作进程。
最简单的代理程序是按节点部署,并与本地进程协同工作。更高级的代理则可以远程启动和管理工作者。代理既可以完全去中心化,根据其管理的工作者做出独立决策,也可以进行协调,与其他代理(这些代理管理同一任务中的工作者)通信以作出集体决策。
以下是管理本地一组工人的代理的示意图。
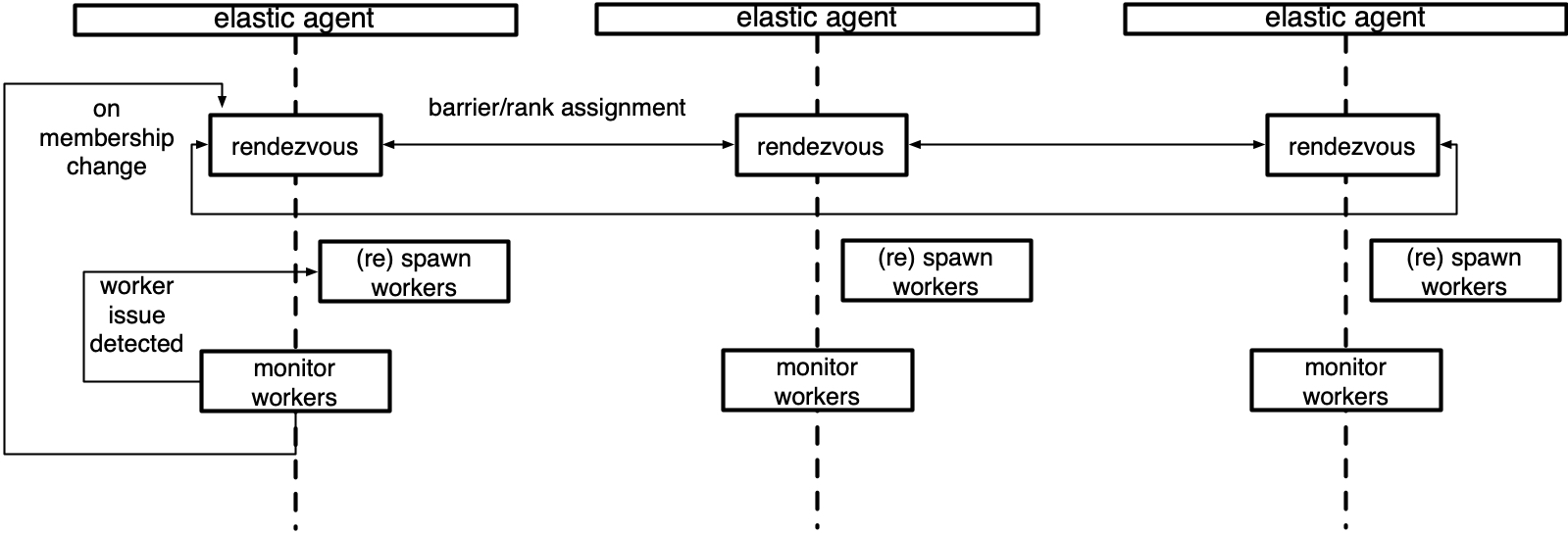
概念
本节介绍了理解torchelastic中agent角色的相关高层级类和概念。
- 类torch.distributed.elastic.agent.server.ElasticAgent[源代码]
-
负责管理一个或多个工作进程的代理程序。
工作进程被视为常规分布的PyTorch脚本。当代理创建这些工作进程时,它会提供所需的信息,以确保工作进程能正确地初始化一个torch进程组。
确切的部署拓扑结构和代理与工人之间的比例取决于代理的具体实现以及用户对作业位置的偏好。例如,要在配备8个训练器(每块GPU一个)的GPU上运行分布式训练任务,可以:
-
使用8个单GPU实例,每个实例放置一个代理,每个代理管理一个工作者。
-
使用 4 个双 GPU 实例,每个实例放置一个代理,每个代理管理两个工作线程。
-
使用 2 个四卡 GPU 实例,每个实例放置一个代理,每个代理管理 4 个工作者。
-
使用 1 x 8 GPU 实例,在每个实例上放置一个代理,每个代理管理 8 个工人。
使用方法
group_result = agent.run() if group_result.is_failed(): # workers failed failure = group_result.failures[0] logger.exception("worker 0 failed with exit code : %s", failure.exit_code) else: return group_result.return_values[0] # return rank 0's results
- abstractget_worker_group(role='default')[源代码]
-
根据给定的
role返回WorkerGroup。请注意,工作线程组是一个可变对象,在多线程或进程环境中其状态可能发生变化。实现者被鼓励(但并非必须)返回一个防御性的只读副本。
- 返回类型
-
- 类torch.distributed.elastic.agent.server.WorkerSpec(role, local_world_size, rdzv_handler, fn=None, entrypoint=None, args=(), max_restarts=3, monitor_interval=0.1, master_port=None, master_addr=None, local_addr=None)[源代码]
-
关于某类特定工人的蓝图信息。
对于给定的角色,只能有一个工作者规格。并且这个规格在所有节点(机器)上应该是相同的,即每个节点为特定规格运行相同数量的工作者。
- 参数
-
-
role (str) – 用户为符合该规格的工作者定义的角色
-
local_world_size (int) – 本地运行的工作进程数量
-
args (元组) — 传递给
entrypoint的参数 -
rdzv_handler (RendezvousHandler) – 负责处理此组工作者的 rdzv
-
max_restarts (int) — 工作进程的最大重启次数
-
monitor_interval (float) – 每隔
n秒监控一次工作者的状态 -
master_port (Optional[int]) – 指定运行 c10d store 的固定端口(在 rank 0 上)。如果没有指定,则选择一个随机的空闲端口。
-
master_addr (Optional[str]) – 固定的 master_addr,用于在 rank 0 上运行 c10d store;如果没有指定,则会使用 agent 的 rank 0 上的主机名。
-
redirects - 将标准流重定向到文件,并可通过传递一个映射表来为特定的本地排名选择性地进行重定向。
-
tee — 将指定的标准输出流同时显示在控制台和文件中,并可通过传递一个映射来选择性地为特定本地排名执行 tee 操作,优先于
redirects设置。
-
- get_entrypoint_name()[源代码]
-
获取入口点的名称。
如果入口点是函数(如
Callable),则返回其__qualname__;如果是二进制文件(如str),则返回二进制文件的名称。
- 类torch.distributed.elastic.agent.server.WorkerState(value)[源代码]
-
WorkerGroup的状态。工作组中的工作者会作为一个整体改变状态。如果其中一个工作者失败了,整个组都会被视为失败。
UNKNOWN - agent lost track of worker group state, unrecoverable INIT - worker group object created not yet started HEALTHY - workers running and healthy UNHEALTHY - workers running and unhealthy STOPPED - workers stopped (interrupted) by the agent SUCCEEDED - workers finished running (exit 0) FAILED - workers failed to successfully finish (exit !0)
一个工作组从初始的
INIT状态开始,然后会进展到HEALTHY或UNHEALTHY状态,并最终达到终止状态,即SUCCEEDED或FAILED。工作节点组可以被代理中断并暂时置于
STOPPED状态。处于STOPPED状态的工作节点将在不久的将来由代理安排重启。以下是一些示例:-
工作节点组故障|发现不健康状态
-
检测到成员变化
当工作组的操作(如启动、停止、rdzv、重试等)失败,并导致操作部分应用于工作组时,状态将变为
UNKNOWN。通常这种情况发生在代理在处理状态变更事件时出现未捕获或未处理的异常。处于UNKNOWN状态的工作组无法由代理恢复,最好让代理自我终止,并允许作业管理器重试该节点。 -
- 类torch.distributed.elastic.agent.server.Worker(local_rank, global_rank=-1, role_rank=-1, world_size=-1, role_world_size=-1)[源代码]
-
一个工作实例。
与此相反,
WorkerSpec表示工人的规格。一个Worker是根据WorkerSpec创建的。Worker相对于WorkerSpec就像对象相对于类。worker的
id由ElasticAgent的具体实现进行解释。对于本地代理,它可以是worker的进程ID(pid,整数),而对于远程代理,则可能被编码为主机和端口(host:port,字符串)。
- 类torch.distributed.elastic.agent.server.WorkerGroup(spec)[源代码]
-
一组
Worker实例。该类为给定的
WorkerSpec定义了一组由ElasticAgent管理的Worker实例。工作群体是否包含跨实例工作者取决于代理的具体实现。
实施
以下是由 torchelastic 提供的代理实现。
- 类torch.distributed.elastic.agent.server.local_elastic_agent.LocalElasticAgent(spec, logs_specs, start_method='spawn', exit_barrier_timeout=300, log_line_prefix_template=None)[源代码]
-
torchelastic.agent.server.ElasticAgent的一个实现,用于处理本地主机的工作者。此代理在每个主机上进行部署,并配置为启动
n个工作进程。当使用 GPU 时,n表示主机上可用的 GPU 数量。本地代理不会与其他主机上的本地代理进行通信,尽管工作者进程之间可能存在跨主机通信的情况。工作者ID被视为本地进程。代理会作为一个整体来启动和停止所有的工作者进程。
工作函数及其参数必须与 Python 多进程兼容。为了将多进程数据结构传递给工作者,你可以在与指定
start_method相同的多进程上下文中创建这些数据结构,并将其作为函数参数传递。exit_barrier_timeout指定了等待其他代理完成的时间(以秒为单位)。这作为一个安全网来处理工人在不同时间完成的情况,防止误将提前完成的工人视为缩放事件。强烈建议用户代码确保工人同步终止,而不是依赖于exit_barrier_timeout。如果在
`LocalElasticAgent`进程中定义了环境变量TORCHELASTIC_ENABLE_FILE_TIMER并将其值设为 1,则可以启用基于命名管道的监视器。可选地,可以通过设置另一个环境变量TORCHELASTIC_TIMER_FILE并指定一个唯一的文件名来配置命名管道。如果未设置环境变量TORCHELASTIC_TIMER_FILE,则`LocalElasticAgent`将内部生成一个唯一文件名,并将其设为环境变量TORCHELASTIC_TIMER_FILE。此环境变量将会传播到工作进程,以便它们能够连接到与`LocalElasticAgent`使用的相同的命名管道。日志会被写入指定的日志目录。默认情况下,每行日志前面会加上前缀
[${role_name}${local_rank}]:(例如:[trainer0]: foobar)。可以通过传递一个模板字符串作为log_line_prefix_template参数来自定义日志前缀。运行时会被替换的宏(标识符)包括:${role_name}, ${local_rank}, ${rank}。例如,要将每行日志的前缀改为全局排名而不是本地排名,则设置log_line_prefix_template = "[${rank}]:。示例启动功能
def trainer(args) -> str: return "do train" def main(): start_method="spawn" shared_queue= multiprocessing.get_context(start_method).Queue() spec = WorkerSpec( role="trainer", local_world_size=nproc_per_process, entrypoint=trainer, args=("foobar",), ...<OTHER_PARAMS...>) agent = LocalElasticAgent(spec, start_method) results = agent.run() if results.is_failed(): print("trainer failed") else: print(f"rank 0 return value: {results.return_values[0]}") # prints -> rank 0 return value: do train
示例启动程序
def main(): spec = WorkerSpec( role="trainer", local_world_size=nproc_per_process, entrypoint="/usr/local/bin/trainer", args=("--trainer-args", "foobar"), ...<OTHER_PARAMS...>) agent = LocalElasticAgent(spec) results = agent.run() if not results.is_failed(): print("binary launches do not have return values")
扩展代理功能
要扩展代理,可以直接实现 ElasticAgent,但建议继承 SimpleElasticAgent,因为它提供了大部分基础结构,并且只需要你实现几个具体的方法。
- classtorch.distributed.elastic.agent.server.SimpleElasticAgent(spec, exit_barrier_timeout=300)[源代码]
-
一个管理特定类型工人角色的
ElasticAgent。一个
ElasticAgent用于管理特定类型的工人角色(例如:WorkerGroup),这些工人对应于单个WorkerSpec。- _assign_worker_ranks(store, group_rank, group_world_size, spec)[源代码]
-
确定工人进程的合适等级。
排名的分配是按照以下算法进行的:
-
每个代理将它的配置(包括 group_rank、group_world_size 和 num_workers)写入公共存储。
-
rank 0 的代理从存储中读取所有角色信息,并为每个代理确定其工作者等级。
-
确定全局排名:每个工人的全局排名是通过将其前面所有工人本地节点大小的累积和来计算的。出于效率考虑,每个工人被分配一个基础全局排名,其范围为[base_global_rank, base_global_rank + local_world_size)。
-
确定角色等级:使用第3点中的算法来确定角色等级,但等级是基于角色名称计算的。
-
rank 0 的代理将分配的排名写入存储。
-
每个代理从存储中读取分配给它的排名。
时间复杂度:每个工作进程 O(1),rank0 为 O(n),总体为 O(n)
- 返回类型
-
-
- _exit_barrier()[源代码]
-
定义一个屏障,确保代理进程在所有工作进程完成后才结束。
等待
exit_barrier_timeout秒,直到所有代理完成执行其本地工作者(无论是否成功)。这样可以防止用户脚本在不同时间终止带来的问题。
- _initialize_workers(worker_group)[源代码]
-
为 worker_group 初始化一组新的工作者。
本质上,这是一个会合操作,之后是调用
start_workers。调用者在调用此方法之前应先调用_stop_workers()来停止正在运行的工作者。将刚启动的工作者组的状态乐观地设置为
HEALTHY,并委托_monitor_workers()方法进行实际状态监控
- abstract_monitor_workers(worker_group)[源代码]
-
查看
worker_group中的工人状态。该函数还会返回工作小组的最新状态。
- 返回类型
- _rendezvous(worker_group)[源代码]
-
为由 worker spec 指定的工人运行会合。
为工作者分配新的全局排名和世界大小,并更新工作组的会合点存储。
- _restart_workers(worker_group)[源代码]
-
重启(包括停止和启动)组中所有的本地工作者。
- abstract_shutdown(death_sig=Signals.SIGTERM, is_restart=False)[源代码]
-
清理代理工作期间分配的所有资源。
- 参数
-
death_sig (Signals) — 发送给子进程的信号,默认为 SIGTERM
- abstract_start_workers(worker_group)[源代码]
-
启动
worker_group.spec.local_world_size指定数量的工作者。这是根据工作小组的工作规格确定的,返回一个从
local_rank到workerid的映射。
- abstract_stop_workers(worker_group, is_restart=False)[源代码]
-
停止指定工作组中的所有工作者。
实现者必须处理所有由
WorkerState定义的状态,包括不存在的工作者和不健康的(卡住的)工作者等,并且需要优雅地应对这些问题。
- 类torch.distributed.elastic.agent.server.api.RunResult(state, return_values=<factory>, failures=<factory>)[源代码]
-
返回工作执行的结果。
运行结果采用“全有或全无”的原则,即只有所有由该代理管理的本地工作者都成功完成时,整个运行才被视为成功。
如果结果成功(例如
is_failed() = False),则return_values字段包含由 THIS 代理管理的工作进程按其全局排名映射的输出(返回值)。也就是说,result.return_values[0]是全局排名为 0 的工作进程的返回值。注意
return_values仅在工作者入口点是函数时有意义。如果工作者的入口点是一个二进制文件,则它通常不会有一个返回值,此时return_values字段是没有意义的,并且可以为空。如果
is_failed()返回True,则failures字段将包含失败信息。这些信息是根据失败工作者的 GLOBAL 秩进行映射的。return_values和failures中的键是互斥的,这意味着一个工作者的最终状态只能是成功或失败。如果根据代理的重启策略被代理故意终止,则该工作者既不会出现在return_values也不会出现在failures中。
代理中的看门狗
如果在 `LocalElasticAgent` 进程中定义了环境变量 TORCHELASTIC_ENABLE_FILE_TIMER 并将其值设为 1,则可以启用基于命名管道的监视器。可选地,可以通过设置另一个环境变量 TORCHELASTIC_TIMER_FILE 并指定一个唯一的文件名来配置命名管道。如果未设置环境变量 TORCHELASTIC_TIMER_FILE,则 `LocalElasticAgent` 将内部生成一个唯一文件名,并将其设为环境变量 TORCHELASTIC_TIMER_FILE。此环境变量将会传播到工作进程,以便它们能够连接到与 `LocalElasticAgent` 使用的相同的命名管道。
健康检查服务器
如果在`LocalElasticAgent`进程中定义了环境变量TORCHELASTIC_HEALTH_CHECK_PORT,则可以在`LocalElasticAgent`中启用健康检查监控服务器。可以通过在指定端口号上启动tcp/http服务器来扩展健康检查接口。此外,健康检查服务器还将通过回调函数检查 watchdog 是否存活。
- 类torch.distributed.elastic.agent.server.health_check_server.HealthCheckServer(alive_callback, port, timeout)[源代码]
-
用于健康检查监控的服务器接口,可以扩展为在指定端口启动tcp或http服务器。
- 参数
- start()[源代码]
-
不支持 PyTorch 的功能,不会启动任何健康检查服务器
- stop()[源代码]
-
用于停止健康检查服务器的函数
- torch.distributed.elastic.agent.server.health_check_server.create_healthcheck_server(alive_callback, port, timeout)[源代码]
-
创建健康检查服务器